嵌入模型在仓库数据向量化中的应用
嵌入模型在仓库数据向量化中的应用
星染应用嵌入模型进行仓库数据向量化:基于 BAAI/bge-large-zh-v1.5 的实践
在智能仓库管理中,如何高效处理和检索海量数据一直是一个挑战。通过嵌入模型,我们可以将仓库中的物品数据、仓库数据、环境数据以及入库出库任务数据转化为高维向量,实现基于语义的相似度检索和聚类分析。本文将详细介绍如何使用 BAAI/bge-large-zh-v1.5 嵌入模型 API 对仓库数据进行向量化处理,并结合代码示例讲解各个实现细节。
1. 背景介绍
随着仓库管理系统的信息化水平不断提升,各种数据(如物品详情、仓库位置、环境监控信息、任务记录等)逐渐呈现多样化和海量化趋势。传统的基于关键词的检索方法往往难以捕捉数据之间的语义关联,而嵌入模型(Embedding Model)能够通过将文本或其他数据转换为向量表示,在高维空间中计算语义相似度,从而实现更智能的数据处理和检索。
2. 模型概述
在本项目中,我选择了 BAAI/bge-large-zh-v1.5 模型。该模型具有以下特点:
- 中文优化:模型针对中文语料进行了大量训练,能够更准确地捕捉中文文本的语义信息。
- 多领域适应性:适用于描述任务、物品、仓库位置以及环境数据等多种数据类型的向量化处理。
- 高效 API 接口:通过 API 调用,可以灵活地将文本数据转换为向量,便于后续的计算和聚类分析。
3. 项目架构与功能
本项目的核心是 VectorService 类,它负责整个向量化过程,包含以下几个关键功能模块:
1. 初始化 OpenAI 接口
首先,通过从配置中读取 API 密钥和基础 URL 来初始化 OpenAI 接口。确保 API 密钥有效且正确设置后,系统才能成功调用嵌入模型 API。
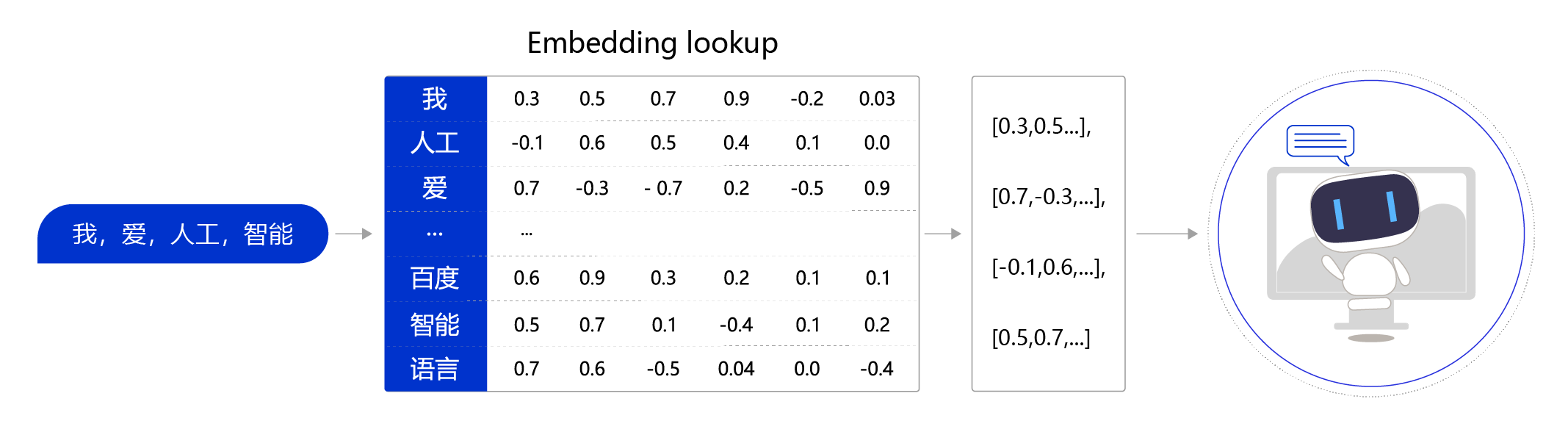
2. 生成嵌入向量
generateEmbedding 方法将传入的文本数据转换为向量表示。在处理文本时,方法会对长文本进行预处理,确保文本不会超出 API 限制(如长度限制),并截取超长文本部分。
3. 向量索引更新
updateWarehouseIndex 方法会从仓库管理系统获取任务、物品、位置和环境数据。逐批调用嵌入模型生成向量,并将生成的向量存入数据库或索引系统,确保数据始终是最新的。
4. 相似度检索
通过 searchSimilar 方法,系统根据查询文本生成向量,并与现有的向量数据进行余弦相似度计算,实现智能的相似度检索。这样,仓库管理系统能够根据用户查询,快速匹配相关数据。
4. 代码示例
1. 初始化 OpenAI 接口 — 以产品描述为例
假设你的仓库管理系统包含多个产品,每个产品都有描述信息。为了让系统能够智能处理产品信息,我们需要将每个产品的描述转化为向量。
场景:
- 假设有一个产品,名为 “苹果”。它的描述是 “新鲜的红色苹果,来自本地农场”。
- 使用 API 密钥初始化接口,系统可以将这个描述转化为向量。
1 | const openai = new OpenAI({ |
这段代码会通过配置的 API 密钥与 OpenAI 模型建立连接,准备将仓库中的产品描述转换为向量。
2. 生成嵌入向量 — 以物品描述为例
假设仓库中有两种物品:苹果和香蕉,它们的描述如下:
- 苹果:新鲜的红色苹果,来自本地农场。
- 香蕉:成熟的黄色香蕉,富含钾元素。
嵌入模型将这些文本转化为高维向量,使得这些文本能在计算机中被理解。
场景:
- 将 “苹果” 和 “香蕉” 的描述传递给嵌入模型,生成对应的向量。
1 | const appleDescription = "新鲜的红色苹果,来自本地农场"; |
3. 向量索引更新 — 以库存数据为例
假设你的仓库有上千种物品,每种物品有详细描述、类别和库存数量。为了提高库存管理的智能化水平,系统将每个物品的描述转化为向量并存入数据库。
场景:
- 例如,你有一个新的物品 “绿茶”,系统会根据其描述生成向量并将其存入向量索引。
1 | const greenTeaDescription = "清香的绿茶,来自浙江,富含抗氧化成分"; |
4. 相似度检索 — 以产品查询为例
当仓库中有成千上万种商品时,管理员希望快速找到与某个产品(如 “红色苹果”)相似的其他物品。通过向量化每个产品描述,系统能够通过计算相似度实现快速检索。
场景:
- 当用户查询 “红色苹果” 时,系统生成查询向量,并与数据库中的其他物品向量计算相似度。
1 | const query = "红色苹果"; |
5. 性能优化与异常处理
在项目实现过程中,我做了以下几项优化:
- 批量处理与并发调用:采用批量处理(如每批 50 条数据)并利用
Promise.all并发请求 API,提高了数据处理的效率。 - 异常处理与后备方案:当 API 调用失败时,系统会生成随机向量作为后备方案,并记录详细日志信息,确保系统在异常情况下依然可以运行。
- 配置缓存:为了避免重复请求配置,
initOpenAI方法中缓存了 API 设置,提升了性能。











