yolo和k210

yolo和k210
星染前言
最近在准备电赛,做到了k210识别数字,网上很多教程都是在maixhub上在线训练的,这几天发现一个问题,如果同时训练会出现排队的问题,等待时间很长,所以我就准备一手本地训练,但是windows本地环境配置不是很方便,所以我选择了Linux。
在成功之前找了很多教程,环境配置出了很多问题,终于找到一个比较方便的。
服务器选择
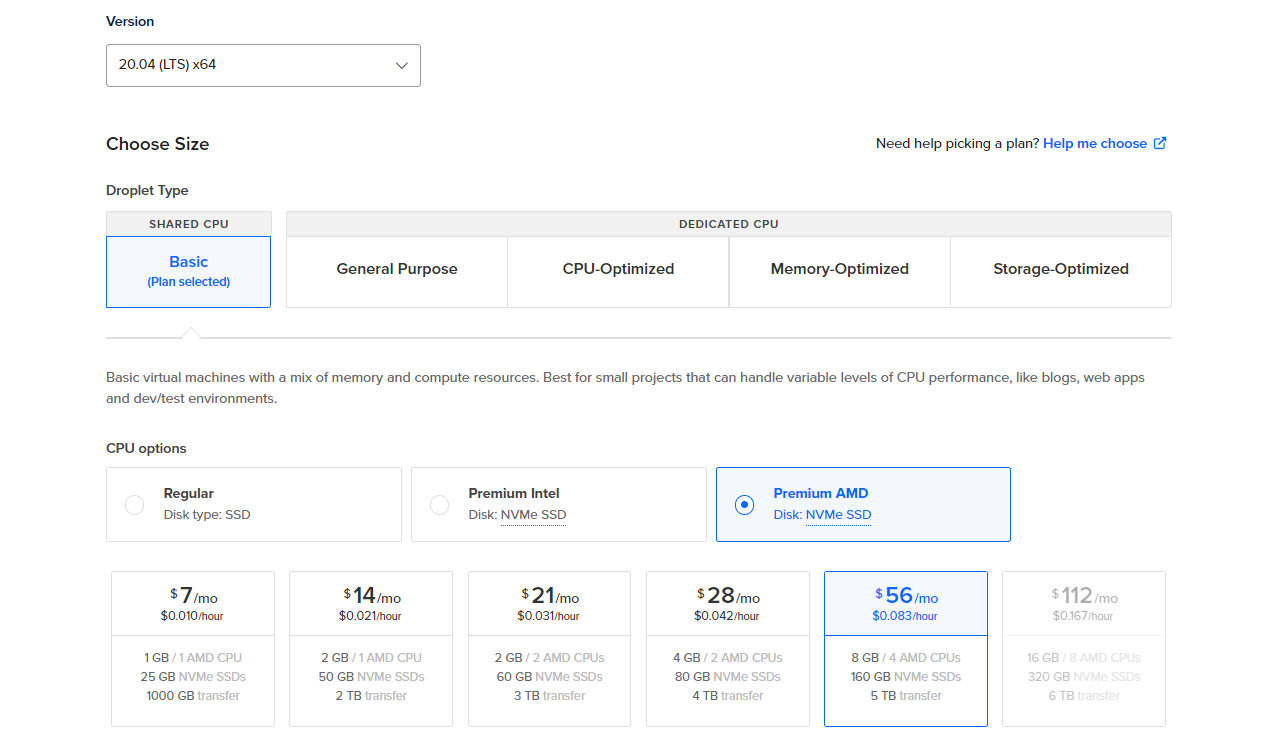
我选择了Digital Ocean的服务器,国外环境,方便下载安装训练环境。
系统推荐安装Ubuntu20.04,环境配置更方便。(我试了好几次,系统重装好几次,这也是我选择云服务器的原因)
环境搭建和模型训练与转换
Docker 和库
在你的机器上安装 Docker 并notebooks在其中创建一个文件夹:
1 | curl -sSL https://get.docker.com | sh |
然后,tensorflow/tensorflow:latest-py3-jupyter使用以下命令部署映像:
1 | sudo docker run -d -p 8888:8888 -v ~/Documents/notebooks/:/tf/notebooks/ tensorflow/tensorflow:latest-py3-jupyter |
我在这里-v解释了该标志:它是一个“绑定安装”。这意味着该文件夹已连接到容器内的文件夹。这使得文件夹(容器)内的数据持久化。否则,如果容器停止,您将丢失文件。~/notebooks/ /notebooks/ /tf/notebooks/
然后,克隆里面的存储库~/notebooks/
1 | cd ~/notebooks/ |
在主机 Web 浏览器中打开以下 URL:http://localhost:8888。您需要令牌才能登录。令牌位于容器内。要获取它,请使用以下命令列出正在运行的容器以获取容器 ID:
1 | docker container ls |
然后,阅读日志并键入:
1 | docker logs 5082a85283bb |
后面的hashtoken=就是登录所需的token。
模型训练、评估和测试
项目本身有一个训练示例,其中训练了 BRIO 。您可以使用 Jupyter Notebook 再次训练模型:training.ipynb。训练的(超)参数从 加载configs/brio.json。
要评估模型,请复制文件夹weights.h5内的文件brio/并打开 Jupyter Notebook:evaluation.ipynb。Notebook 加载模型,获取内部图像datasets/brio/images_test/,对其进行评估并将结果保存在 evaluation/detected/下。
要训练新模型,您需要json在文件夹内创建一个文件configs/。您可以configs/brio.json作为参考。此外,您需要有足够的图像(例如datasets/brio/images/brio_8.jpg),并且需要为每个图像创建一个注释文件(datasets/brio/xml/brio_8.xml)。
1 | <annotation verified="yes"> |
首先更改folder,filename和path。之后,设置图像size和物体所在边界框(bndbox)的坐标。您还可以定义pose、truncated和difficult参数以获得更好的检测。最后一步是可选的,但它可以有很大帮助。
标记图像后,将它们分为两组:训练(例如brio/images/,brio/xml/)和评估(例如brio/images_valid/,brio/xml_valid/),并获取一些其他图像作为测试集(您不需要这些图像的注释文件)。这些集合的路径在配置文件中定义(configs/brio.xml)。
你也可以在配置文件中调整超参数,例如actual_epoch(实际训练轮数)、batch_size(批量大小)、learning_rate(学习率)、anchors(先验锚点)或train_times(训练次数)。它们会影响模型的最终性能。例如,如果你拥有更大的数据集,其中包含更多的训练图像和检测类别,为了更好地收敛,应该增加训练轮数(actual_epoch)。或者,如果图像中的目标通常较小,可以使用较小的锚点参数(anchors)。这定义了检测器(YOLOv2)的先验锚点。如果图像数量有限,可以增加train_times以提高训练效果,或将jitter设置为true。这样可以启用图像增强,包括调整大小、平移和模糊处理图像,以防止过拟合并在数据集中引入更多的变化。此外,它还会随机翻转图像。然而,如果你的对象对方向敏感,应将其设置为false。
将模型另存为tflite
在训练完模型后,你会得到两个文件:weights.h5和weights.tflite。第二个文件是将TensorFlow模型转换为TensorFlow Lite的结果,可以将其转换为可加载到Sipeed MAix板上的kmodel。
作者已经将原始存储库更新为TensorFlow 2.0版本。文件yolo/backend/utils/fit.py中保存了tflite模型(def save_tflite(model):)。TensorFlow 2.0有一个直接将TensorFlow模型转换为tflite模型的函数。
1 | converter = tf.lite.TFLiteConverter.from_keras_model(model) |
然而,生成的文件只能使用nncase版本大于0.2.0进行转换才能得到kmodel,否则会出现以下错误:
1 | Fatal: Layer TensorflowReshape is not supported |
如果你使用的是nncase v0.2.0版本,你会得到一个V4 kmodel,这与MicroPython上运行的KPU库(仅支持V3)不兼容。试图在KPU上加载V4模型会导致以下错误:
1 | v=1263354956, flag=4, arch=0, layer len=1, mem=1926400, out cnt=127 |
因此,你需要使用nncase v0.1.0 RC5,并使用以下代码将TensorFlow模型转换:
1 | model.save("weights.h5", include_optimizer=False) |
这两个选项都包含在yolo/backend/utils/fit.py文件中。第二个选项只是激活状态的。
转换tflite为kmodel模型
首先,从 GitHub 存储库获取 MAix 工具箱:
1 | git clone https://github.com/sipeed/Maix_Toolbox.git |
并修复文件内的一个小错误get_nncase.sh
1 | cd Maix_Toolbox |
然后,下载库nncase并键入:
1 | ./get_nncase.sh |
为了转换模型,nncase需要一些示例图像进行推理。这些示例图像的分辨率必须与模型输入图像的分辨率相同。输入大小在配置文件中定义brio.json为:
1 | { |
文件夹中包含了一些示例datasets/brio/images_maixpy。图像的大小为 224x224 像素。将这些图像放在images里面的一个文件夹中Maix_Toolbox,并将weights.tflite文件也复制到该Maix_Toolbox文件夹中。最后,将 Tensorflow Lite 模型转换为.kmodel使用:
我使用我的一个工具进行转换
1 | ./tflite2kmodel.sh weights.tflite |
如果成功转换模型,您将获得一个weights.kmodel文件,您将看到:
1 | usage: ./tflite2kmodel.sh xxx.tflite |
部分问题解决
ModuleNotFoundError: No module named ‘sklearn’
1 | pip install -U scikit-learn scipy matplotlib |
No module named ‘sklearn.utils.linear_assignment_’
1 | pip install scikit-learn==0.22.2 |
提示需要升级pip
直接在外部升级pip依旧会报错,因为是在docker中的环境,所以可以得进入docker中进行升级,但我发现jupyter notebook中有个终端,可以直接在里面升级
1 | pip install --upgrade pip |
写在最后
第一次做确实有点难度,会报错很多,一个一个查找解决,能学到了很多。不一定需要服务器,可以使用windows虚拟机,但我折腾几天有点受不了,所以换服务器了。
标注可以在网站上标注,也可以使用本地标注,推荐vott。
好久没写博客了,写的不好请多多包涵。